Large Language Model (LLM) Augmenter
Detailed guide to using the LLM Augmenter. This page also serves as a proof of concept for the LLM Augmenter.
Introduction
The LLMAugmenter offers an advanced dataset augmentation technique that leverages large language models (LLMs) for paraphrasing and summarization. By generating diverse rephrasings and summaries of input data, this augmenter helps prevent overfitting in text-based sentiment classification models by adding rich variability to the training dataset.
Overview
The LLMAugmenter provides a robust solution to augment text data, reducing the risk of overfitting and enhancing model performance in NLP tasks. This augmenter relies on two distinct LLM-driven techniques to achieve variability in the dataset:
- Paraphrasing via Questioning
- Summarization
Paraphrasing via Questioning
The Paraphrasing via Questioning technique in LLMAugmenter uses a large language model (LLM) to rephrase sentences by framing the task as a question-answering exercise. This approach prompts the model to reword sentences without repeating the same verbs or phrases, generating a unique paraphrase that maintains the original meaning but provides distinct wording. By framing the task as a question-answer prompt, the model's responses are directed towards producing a rephrased answer, adding both lexical and structural diversity.
By generating multiple paraphrased versions of the same text, LLMAugmenter introduces subtle variations that help the model learn more generalized features of the language. This variation reduces the chances of overfitting, as the model isn't exposed to identical sentences repeatedly.
Paraphrased sentences, with different structures and vocabulary, prepare the model to handle a broader range of linguistic patterns, improving its robustness in real-world applications.
As the LLM avoids verb repetition while rephrasing, it deepens the model's understanding of summarizes and related terms, which is especially beneficial for tasks like sentiment analysis, where nuanced language is common.
Parameters
sentence(str) - Input text to augment
example: 'This is a test sentence.'
max_new_tokens(int) - Maximum number of new tokens that can be introduced to the output sentence.
default: 512
Usage Example
Summarization
The Summarization technique in LLMAugmenter utilizes a transformer-based summarizer model, specifically the BART model, to condense longer texts or passages into shorter, yet semantically complete summaries. This technique is especially useful for extracting core information from large documents or verbose sentences.
In NLP tasks, long sentences or paragraphs may contain extraneous information. Summarization helps reduce this noise by retaining only the most important information.
Ultimately, training on both long-form text and its summaries helps the model develop a nuanced understanding of essential versus non-essential details. This ability to differentiate relevant information is invaluable in tasks that require prioritization of critical data, like summarization, classification, and even information extraction.
Parameters
text(str) - Input text to augment.
example: 'This is a test sentence.'
max_length(int) - Maximum length of the summary.
default: 100
min_length(int) - Minimum length of the summary.
default: 30
Usage Example
Full Example of LLM Summarizer Augmentation
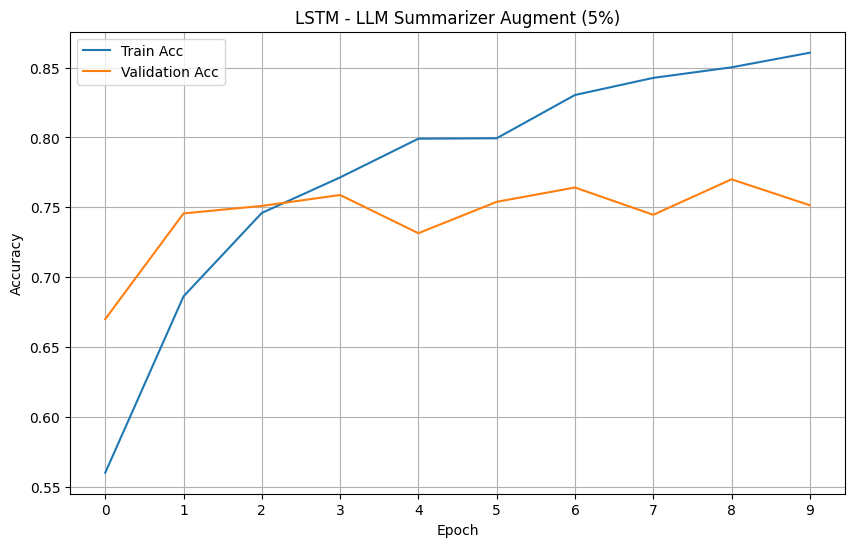
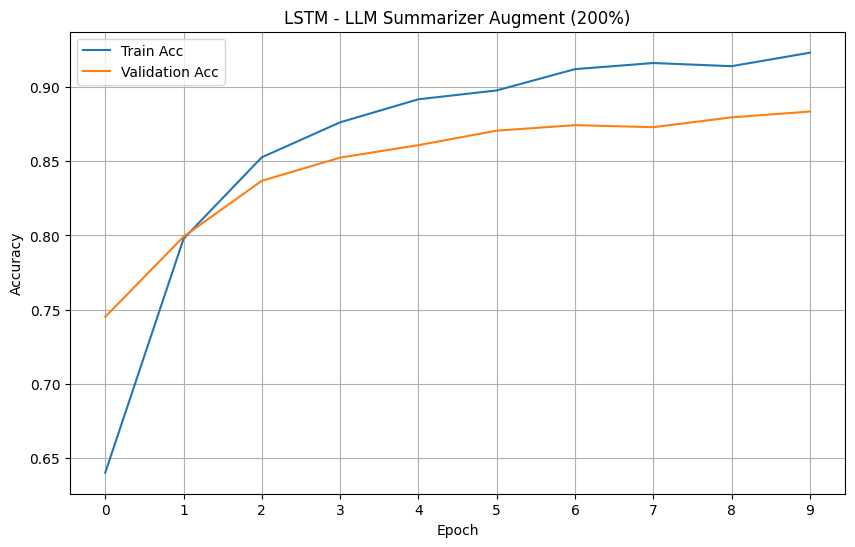
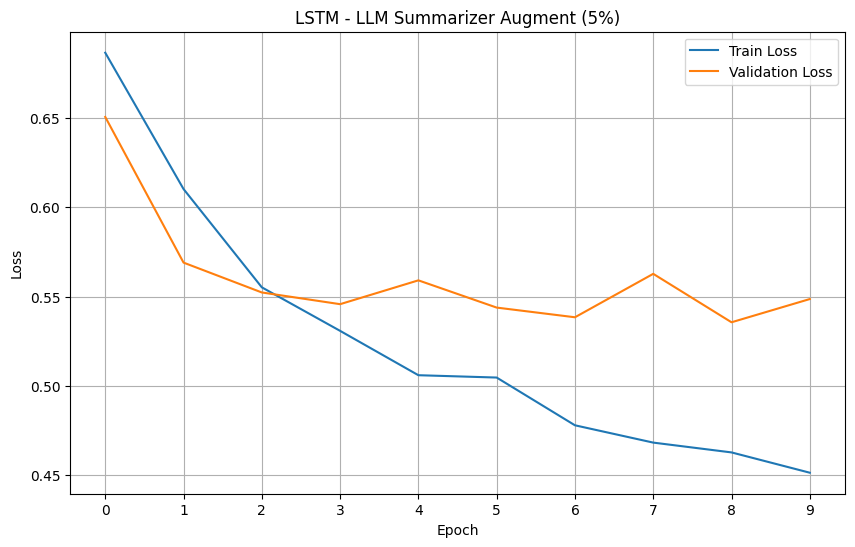
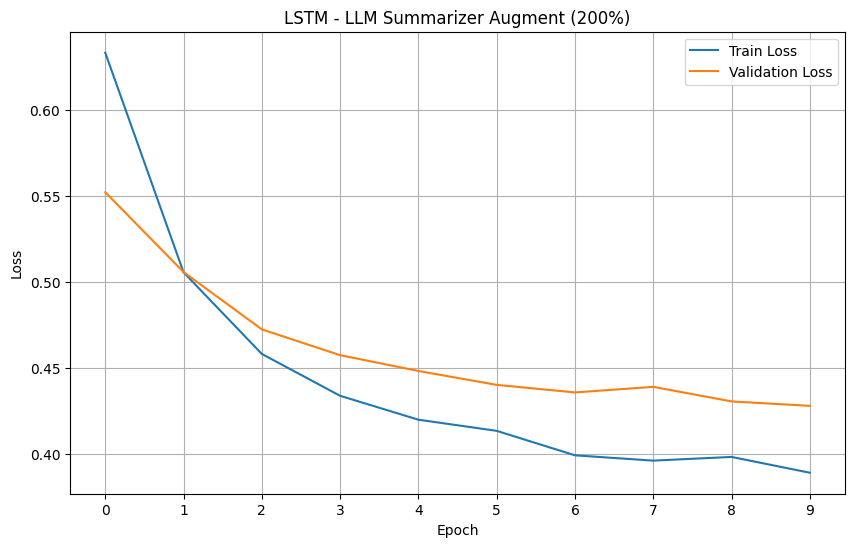
For your reference, below is a full example of the NLarge LLM Summarizer Argumentation on a dataset. This example will also function as a proof of concept for the NLarge LLM Summarizer Augmentation. This example will be evaluating augmented datasets on LSTM based on the loss and accuracy metrics. We have chosen the 'rotten tomatoes' dataset due to it's small size that is prone to overfitting.
Full Code:
Models' Loss
Models' Accuracy