Random Augmenter
Detailed guide to using the Random Augmenter. This page also serves as a proof of concept for the Random Augmenter.
Introduction
We will be explaining the different modes of the Random Augmenter, including an example using the 'Rotten Tomatoes' dataset later on.
As we can observe from the name of the augmenter, the Random Augmenter revolves around using a probability defined to modify a sequence. The random augmentation process involves iterating over each word in the sequence and performing the defined Action with a predefined probability. This introduces variability into the dataset, potentially improving the robustness and generalization capabilities of NLP models. Before we begin the explanation for each Action mode, let's first import and initialize the augmenter.
Importing & initializing the library
Before using the library, you should first import and initialize the random augmenter. Since there are different modes to the Random Augmenter, be sure to import the Action class too!
Import & Initialize NLarge Random Augmenter:
Great! Now let us go through each Random Augment Mode.
Random Swap
The Swap Action randomly samples the target sequence with the predefined probability and swaps it's position with the adjacent words if the sampled word is not in the 'stop_words' argument.
Arguments:
dataInput text to augment
actionAction to perform, in the case of using Random Swap, action=Action.SWAP
aug_percentPercentage of words in sequence to augment
aug_minMinimum number of words to augment
aug_maxMaximum number of words to augment
skipwordsList of words to skip augmentation
Random Substitute
The Substitute Action randomly samples the target sequence with the predefined probability. It then substitutes the sampled word(s) with words chosen randomly in the provided 'target_words' argument if the sampled word(s) is not in the 'stop_words' argument.
Arguments:
dataInput text to augment
actionAction to perform, in the case of using Random Substitute, action=Action.SUBSTITUTE
aug_percentPercentage of words in sequence to augment
aug_minMinimum number of words to augment
aug_maxMaximum number of words to augment
skipwordsList of words to skip augmentation
target_wordsList of words to substitue with the original sampled word
Random Delete
The Delete Action randomly samples the target sequence with the predefined probability. It then deletes the sampled word if the sampled word is not in the 'stop_words' argument.
Arguments:
dataInput text to augment
actionAction to perform, in the case of using Random Delete, action=Action.DELETE
aug_percentPercentage of words in sequence to augment
aug_minMinimum number of words to augment
aug_maxMaximum number of words to augment
skipwordsList of words to skip augmentation
Random Crop
The Crop Action randomly samples a starting index and a ending index in the target sequence. The set of continuous words from the sampled starting to the sampled ending index will then be checked for the existence of stopwords. If the set of continuous words does not contain 'stopwords', it will be deleted.
Arguments:
dataInput text to augment
actionAction to perform, in the case of using Random Delete, action=Action.DELETE
aug_percentPercentage of words in sequence to augment
aug_minMinimum number of words to augment
aug_maxMaximum number of words to augment
skipwordsList of words to skip augmentation
Example of Random Augmentation
For your reference, below is a full example of the NLarge Random Argumentation on a dataset. This example will also function as a proof of concept for the NLarge Random Augmentation. This example will be evaluating augmented datasets on RNN and LSTM based on the loss and accuracy metrics. We have chosen the 'rotten tomatoes' dataset due to it's small size that is prone to overfitting.
Importing libraries:
Downloading 'rotten-tomatoes' dataset
Here, we download the dataset and ensure that the features are in the correct format for our dataset augmentation later on.
Applying augmentation and enlarging dataset
We will be performing a 10% Random Substitute Augmentation and a 100% Random Substitute Augmentation on the dataset. This would increase the dataset size by 10% and 100% respectively.
RNN: Loading the pipeline & model training
Here, we will initialize and train the pipeline using RNN and the augmented datasets.
RNN: Evaluating the models' performance
Plotting the loss and accuracy graphs, we can visualize the performance improvements between the two amount of augmentation on RNN.
Looking at the graphs, we can see a stark improvement on both loss and accuracy of the RNN model.
Models' Loss
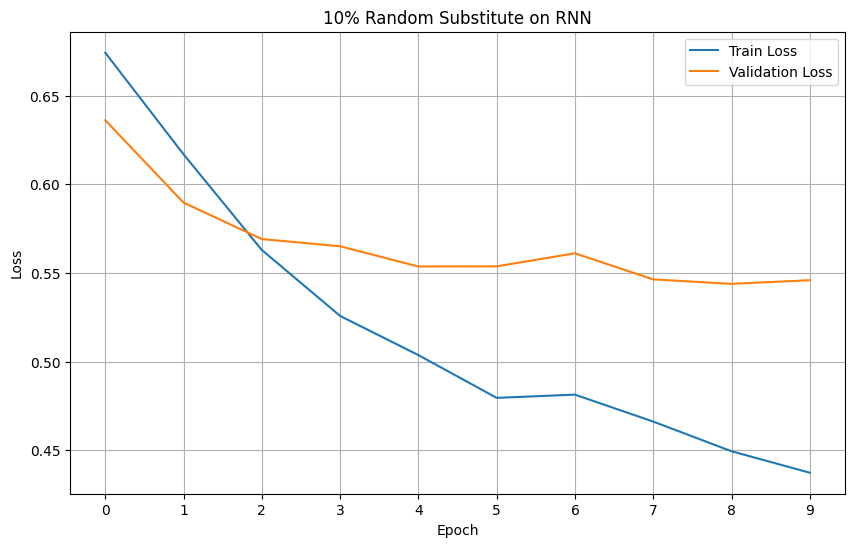
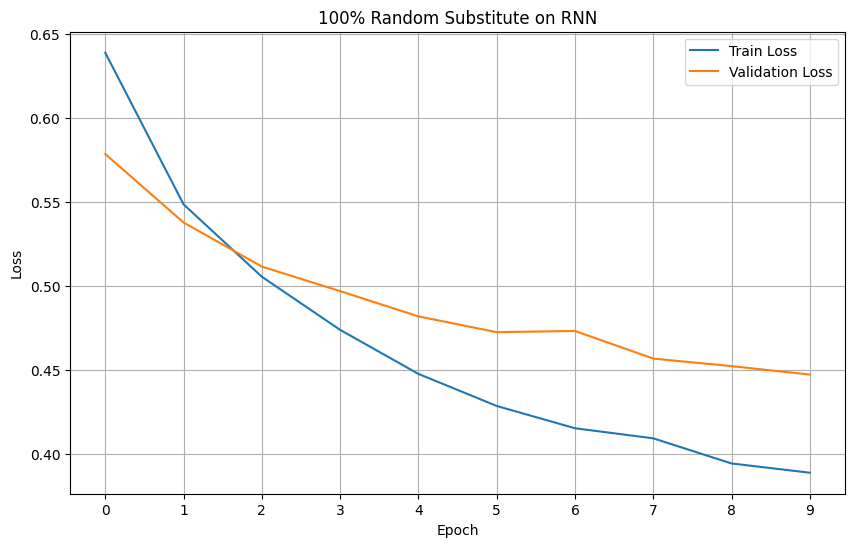
Models' Accuracy
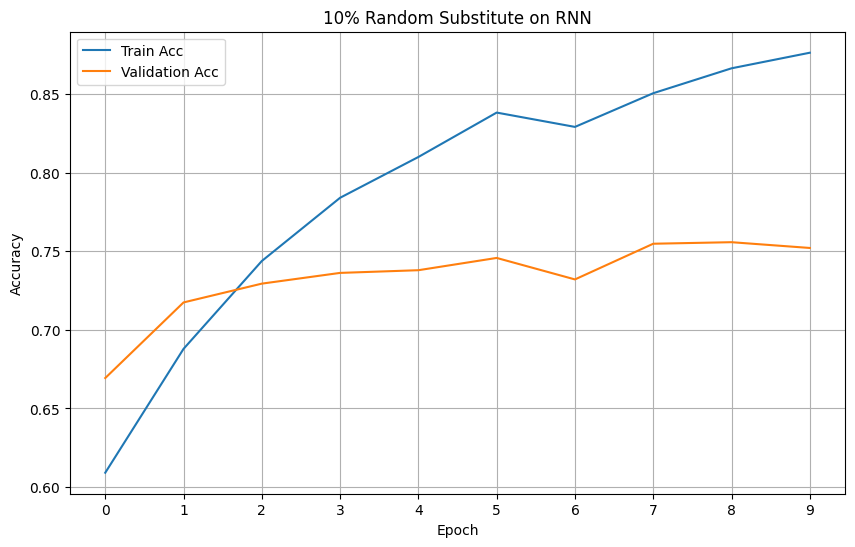
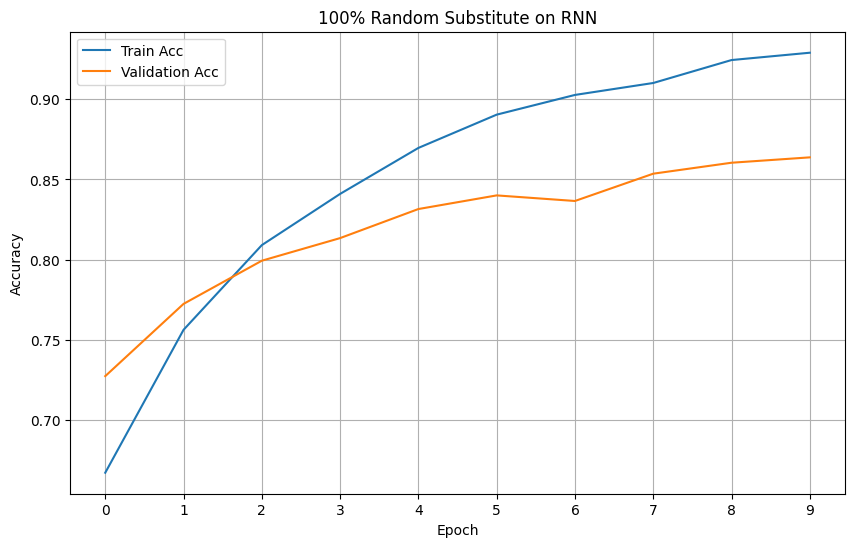
LSTM: Loading the pipeline & model training
Here, we will initialize and train the pipeline using LSTM and the augmented datasets.
LSTM: Evaluating the models' performance
Plotting the loss and accuracy graphs, we can visualize the performance improvements between the two amount of augmentation when used on LSTM.
Looking at the graphs, we can see a stark improvement on both loss and accuracy of the LSTM model.
Models' Loss
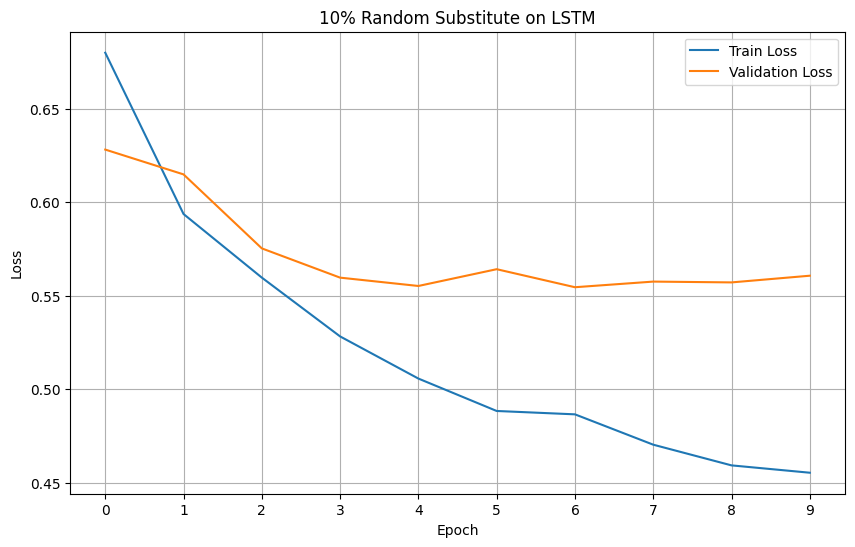
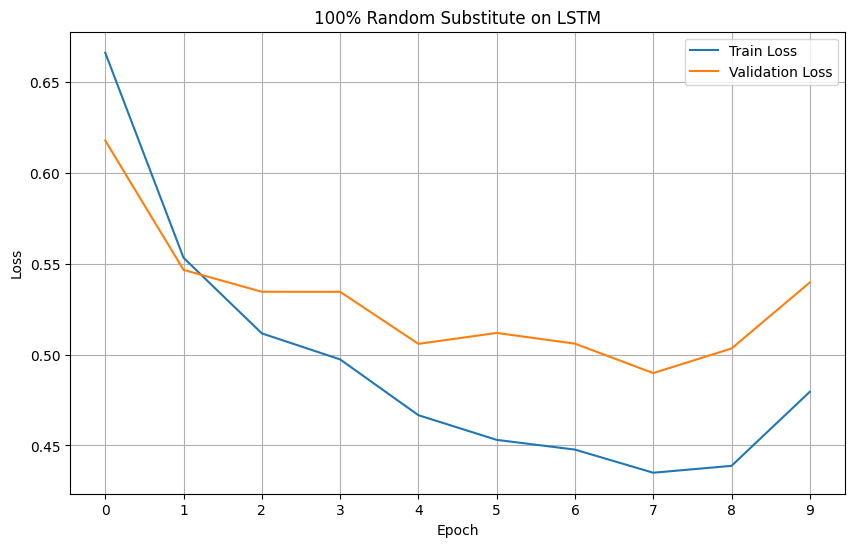
Models' Accuracy
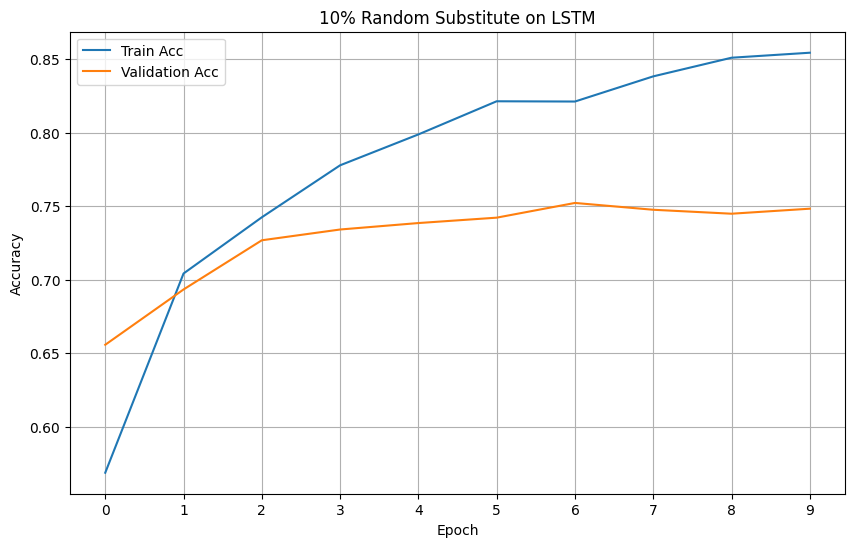
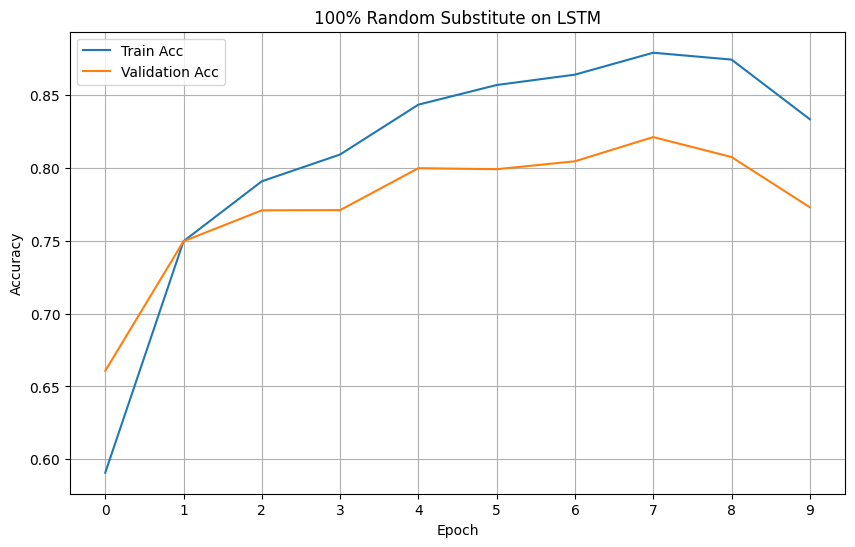
Analysis of Results
The results of our experiment indicate that the performance of the models keeps increasing with higher levels of augmentation. This suggests that data augmentation provides a clear benefit for sentiment classification tasks. Additionally, the findings highlight the importance of data augmentation in enhancing the diversity and robustness of training datasets, leading to imporved model performance.
The data augmentation techniques mitigates overfitting by effectively increasing the size of the training dataset, reducing the likelihood of the model memorizing specific examples and encouraging it to learn general patterns instead. The introduction of variations in the training data makes the model more robust to noise and variations in real world input data, which is crucial for achieving good performance on unseen data.