Synonym Augmenter
Detailed guide to using the Synonym Augmenter. This page also serves as a proof of concept for the Synonym Augmenter.
Introduction
The Synonym Augmenter enables data augmentation for text sentiment classification by introducing variability in text through synonym replacement. This augmenter enhances a dataset by augmenting words with their synonyms, which can improve model robustness by introducing semantic variability without changing a sentiment.
The Synonym Augmenter samples word in the target sequence with a predefined probability and replace it with a randomly chosen synonym from a set of synonyms of the sampled word.
In the current version of NLarge, the set of synonyms can also be drawn from WordNet, an extensive lexical database.
Key Components
WordNet
WordNet provides synonym and antonym lookup, with optional parts of speech (POS) filtering. The POS tagging functionality identifies relevant grammatical structures for more accurate augmentation.
PartsOfSpeech
Our POS functionality maps between POS tags and constituent tags to ensure compatibility with WordNet's POS requirements.
The current version supports noun, verb, adjective and adverb classifications.
SynonymAugmenter
The augmenter uses the WordNet class to perform augmentation by replacing words with synonyms based on user-defined criteria. It utilizes POS tagging to determine eligible words for substituition, while skip lists (stop words and regex patterns) can prevent certain words from being replaced.
Import & Initialize NLarge Synonym Augmenter
Before we proceed further, let us first import and initialize the SynonymAugmenter instance.
Parameters
data(str) - Input text to augment
example: 'This is a test sentence.'
aug_src(str) - Augmentation source, currently supports only "wordnet".
default: 'wordnet'
lang(str) - Language of the input text.
default: 'eng'
aug_max(int) - Maximum number of words to augment.
default: 10
aug_p(float) - Probability of augmenting each word.
default: 0.3
stopwords(list) - List of words to exclude from augmentation.
default: None
tokenizer(function) - Function to tokenize the input text.
default: None
reverse_tokenizer(function) - Function to detokenize the augmented text.
default: None
Single Sentence Usage Example
Full Example of Synonym Augmentation
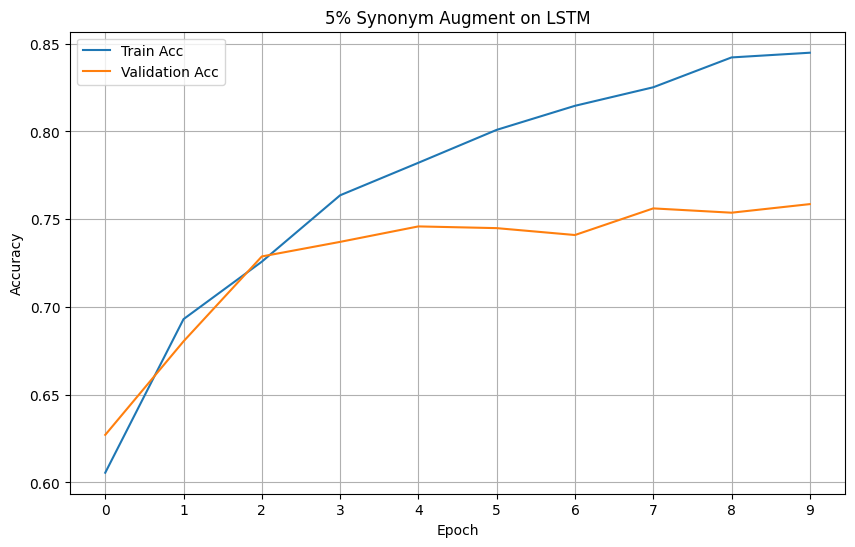
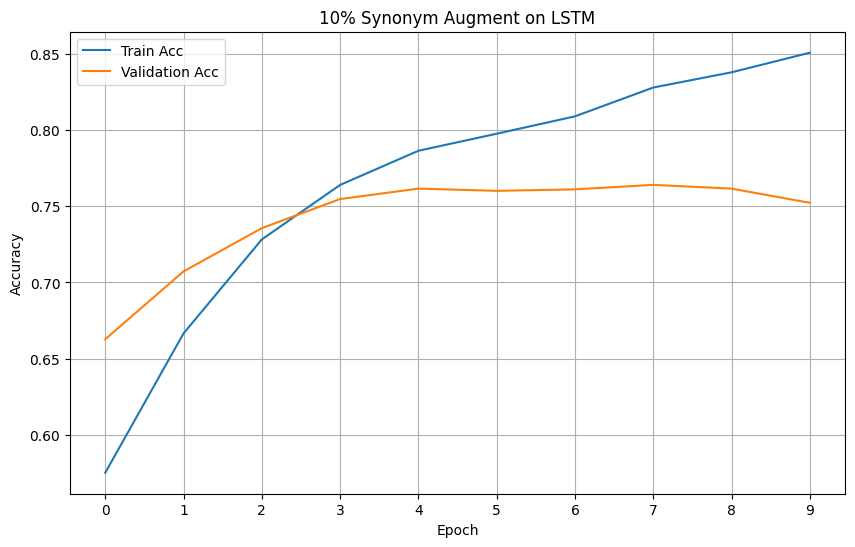
For your reference, below is a full example of the NLarge Synonym Argumentation on a dataset. This example will also function as a proof of concept for the NLarge Synonym Augmentation. This example will be evaluating augmented datasets on LSTM based on the loss and accuracy metrics. We have chosen the 'rotten tomatoes' dataset due to it's small size that is prone to overfitting.
Full Code:
Models' Loss
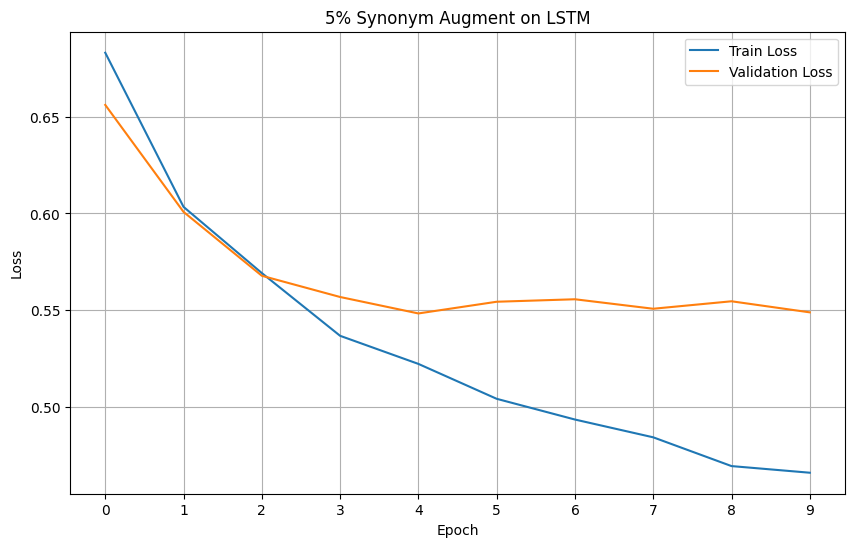
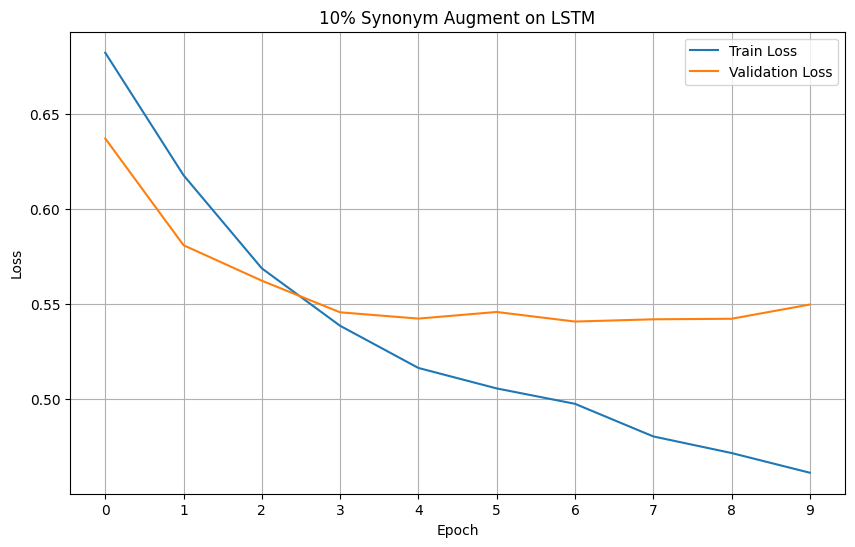
Models' Accuracy